潮人地東莞seo博客小編下面跟大家分享關(guān)于seo網(wǎng)站心得之搜索引擎同義詞反饋機制【百度搜索研發(fā)部】等問題,希望seo專員在做seo優(yōu)化的過程中有所幫助,內(nèi)容僅供參考。

seo網(wǎng)站心得之搜索引擎同義詞反饋機制【百度搜索研發(fā)部】
由于搜索算法本身的局限性,對于用戶的語義、意圖等理解不夠,而基于用戶行為的點擊調(diào)權(quán),作為對傳統(tǒng)搜索算法的補充,在搜索中扮演著重要的作用。盡管用戶行為已經(jīng)被證明在搜索中的效果,但是一直只是停留在query-url層面,或者ngram-url層面,沒有深入反饋到檢索算法中的基礎(chǔ)策略,比如:同義詞、緊密度、省略等,這些策略影響了url與query之間的關(guān)系。本文以對同義詞的反饋為例,提出一個通用的基于用戶行為的基礎(chǔ)策略反饋框架。
由于同義詞詞典與線上應(yīng)用算法的限制,檢索系統(tǒng)中存在部分質(zhì)量不好、或者本來質(zhì)量好但是應(yīng)用時錯誤降低了權(quán)值的同義詞。在同義詞召回出來結(jié)果后,呈現(xiàn)在用戶面前,用戶的行為數(shù)據(jù)可以幫助我們識別同義詞的好壞。在計算出同義詞的好壞后,就可以直接應(yīng)用于同義詞的退場或者調(diào)整應(yīng)用的權(quán)值。
seo博客相關(guān)推薦閱讀:seo優(yōu)化技術(shù):大連seo網(wǎng)站推廣(大連seo顧問)
反饋框架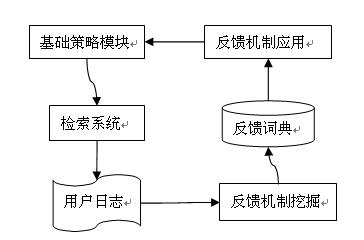
在進行反饋機制的挖掘中,主要分為三部分:
日志記錄。主要進行基礎(chǔ)策略用戶行為的記錄、以及query-url對進行用戶行為數(shù)據(jù)的統(tǒng)計,解決如何利用用戶行為衡量query-url轉(zhuǎn)義問題。這部分還要記錄影響具體query-url的策略,比如,這個url是哪個同義詞所召回,或者是哪個term被省略。反饋機制挖掘。根據(jù)query-url中統(tǒng)計的基礎(chǔ)策略的用戶行為數(shù)據(jù),進行基礎(chǔ)策略的統(tǒng)計。這個地方不同的基礎(chǔ)策略的衡量方式可以保持相同,但是基礎(chǔ)策略提取的信息不一樣。比如同義詞是替換對,省略是指省略的term等。?線上反饋應(yīng)用。將第二步挖掘的詞典,應(yīng)用于具體的query,比如進行上下文的匹配,以及一些應(yīng)用策略。
以上的框架比較籠統(tǒng),下面針對同義詞的反饋做具體的討論。
日志記錄及統(tǒng)計這部分首先需要記錄具體的策略,比如在這個query下,每條url是由哪個基礎(chǔ)策略所影響的,而且需要更加具體。比如同義詞需要記錄由那些具體的同義詞所召回。因為往往一個query有很多同義詞,但是真正每條url只是其中1到2個同義詞影響的。
衡量query-url是否轉(zhuǎn)義是非常關(guān)鍵的步驟,本文主要篇幅是討論這個。衡量的方法需要借助用戶的行為。在搜索引擎的日志系統(tǒng)中,對query-url有如下的用戶行為統(tǒng)計量:(下面的討論中,url的統(tǒng)計都是和query相關(guān)的,不再特殊說明)
展現(xiàn)次數(shù):用戶搜索后,搜索引擎返回的url在前k條展現(xiàn)的次數(shù)(display)
點擊次數(shù):用戶點擊url次數(shù)(click)
滿意點擊次數(shù):考慮是否滿足用戶的需求的點擊(相對停留時間,是否是最后點擊) (satisfy)
因此我們可以用click/disply、satisfy/display來衡量url的好壞。但有如下問題:
1.位置偏置問題:點擊次數(shù)對位置非常敏感,搜索結(jié)果中, url的點擊次數(shù)隨著url的排序位置越靠后,其點擊次數(shù)越少,而且越后面減少得越快。因此位置在前的url,雖然轉(zhuǎn)義了,但也有很多用戶點擊;反之,位置在后的url,雖然滿足用戶需求了,但也很少有用戶點擊。這樣很容易讓我們的反饋系統(tǒng)失效。
2.在搜索引擎中,用戶對搜索結(jié)果的滿意大致可以分為兩個層次:
1) 檢索出來的url的標(biāo)題和摘要是否和用戶的query的意圖一致。
2) url內(nèi)容的質(zhì)量是否滿足用戶的需求,比如是否死鏈、知道頁面沒有人回答、作弊頁面等。我們的目標(biāo)是識別出轉(zhuǎn)義的替換詞對,這些只和第1個層次的滿意相關(guān)。我們可以假設(shè)用戶既然點擊了這個url,說明這個url的title摘要是沒有轉(zhuǎn)義的,至于網(wǎng)頁的質(zhì)量不是同義詞本身的質(zhì)量所能影響的。
為了解決問題1,可以從這一角度考慮。排在后面的url點擊次數(shù)少的原因是用戶看到的次數(shù)少,因此不能用展現(xiàn)來與click做比值,可以利用一些方法來估計用戶看到的次數(shù),我們稱之為檢查次數(shù)(check)。這里有一些很簡單的方法。比如對于每次用戶的搜索,用戶最后點擊的url位置為p,那么位置在p之前url檢查次數(shù)是1,在p之后的url的檢查次數(shù)依次以一個概率衰減。這些概率可以采用一些貝葉斯的方法進行學(xué)習(xí)。
采用檢查次數(shù)可以部分解決位置偏置問題,但是學(xué)習(xí)到的衰減參數(shù)是對所有的query-url,但不同的query-url有很大的差別,這也是該方法的不足之處。
反饋挖掘和應(yīng)用反饋挖掘基于第3章中日志記錄的工作,可以采用click次數(shù)用來表示url滿足query的次數(shù),而check-click表示url不滿足query的次數(shù)。這樣用click/(check-click)這個值來表示url滿足query程度。對于具體的同義詞反饋任務(wù),可以把多條query-url結(jié)果中記錄的同樣的同義詞替換進蓋州seo網(wǎng)站排名優(yōu)化行統(tǒng)計click和check次數(shù)(即統(tǒng)計的key是 原詞 替換詞 二元組),把最后得到的click/(check-click)作為衡量這個同義詞替換的相似度,即同義詞的反饋替換相似度:
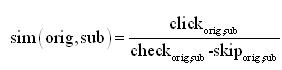
這個地方還有一大問題是,由于很多同義詞是上下文相關(guān)的,比如:考慮一對同義詞 看->治療,在某些上下文下,比如:哪里看病比較好,是同義的;而在某些上下文下,比如:哪里看還珠格格連播。因此為了更智能的在不同的上下文進行同義詞的反饋,需要在統(tǒng)計的時候考慮上下文,即統(tǒng)計的key為:原詞 上下文 替換詞 三元組。
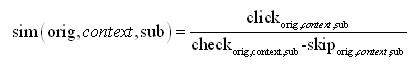
但是不能把整個query作為上下文,這樣統(tǒng)計會有很大的數(shù)據(jù)稀疏性,而如果隨便把單個詞作為上下文,會有很大的準(zhǔn)確率問題。比如 哪里 對 看->治療 以及看->觀看 都是支持的。因此為了兼顧上下文數(shù)據(jù)的稀疏以及準(zhǔn)確問題,需要一個上下文選擇算法。在自然語言處理中通常采用似然比的方法(llr, likelihood ratio)[3],用來衡量orig與context的搭配強度,從而搭配強度越強,這個context詞可以認(rèn)為是orig詞的替換上下文。其計算方法為:
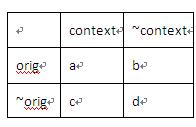
其中a表示orig,context共現(xiàn)次數(shù);b表示orig出現(xiàn),context不出現(xiàn)的次數(shù);c表示orig不出現(xiàn),context出現(xiàn)的次數(shù);d表示oirg和context都不出現(xiàn)的次數(shù)。N=a+b+c+d表示總共的樣本數(shù),那么llr的計算公式為:
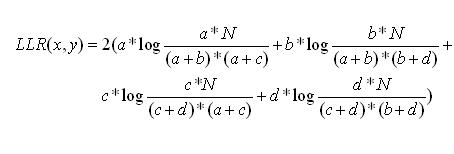
反饋應(yīng)用反饋機制應(yīng)用時網(wǎng)站網(wǎng)頁seo優(yōu)化,是針對每一個替換進行獨立的判斷,即已知替換對(orig sub),需要先進行上下文的選取。上下文相關(guān)的同義詞,本質(zhì)上來說被替換詞是一個多義詞,對于大部分query來說,只用一個上下文詞就可以限定被替換詞的意義。因此從簡單的角度考慮,以及多個詞的上下文融合所帶來的噪音以及融合方式的問題,反饋機制應(yīng)用時只選擇一個在一定上下文窗口內(nèi)的詞語。
最后計算所選擇的上下文,利用4.1節(jié)中訓(xùn)練的數(shù)據(jù),作為替換的反饋相似度,即sim(orig,contex,sub)。利用這個值作為同義詞的置信度應(yīng)用于線上:或退場,或降權(quán),或升權(quán)。
總結(jié)和展望在檢索系統(tǒng)中,對基礎(chǔ)策略做基于用戶行為的反饋是一個比較新的方向,對于改進基礎(chǔ)數(shù)據(jù)具有非常重要的意義。本文根據(jù)對用戶行為的深入調(diào)研,探討了一些方法和指標(biāo)。
從總體上來說,本框架的相當(dāng)于做了兩個假設(shè):用戶行為與相關(guān)性的關(guān)系正相關(guān),url相關(guān)性與基礎(chǔ)策略正確性正相關(guān)。
第一個假設(shè)涉及到基礎(chǔ)統(tǒng)計特征的調(diào)研思考角度。點擊 檢查是體現(xiàn)這些關(guān)系的特征之一,另外還可以考慮更多的特征,比如:滿意點擊,點擊的url條目。還有飄紅對點擊的影響,用戶的作弊識別等干擾基礎(chǔ)特征的統(tǒng)計。這一點不同的基礎(chǔ)策略是可以統(tǒng)一的
第二個假設(shè)涉怎么做網(wǎng)站優(yōu)化seo及到基礎(chǔ)策略以什么形式來表示這些基礎(chǔ)的統(tǒng)計特征。這個是和基礎(chǔ)的策略緊密相關(guān)。比如同義詞選擇上下文的方法,以及上下文的位置,多個上下文,或者不需要上下文的替換對識別等。另外還需關(guān)注基礎(chǔ)策略的應(yīng)用問題,比如同義詞不轉(zhuǎn)義,url轉(zhuǎn)義的問題,這對基礎(chǔ)策略的識別會產(chǎn)生誤導(dǎo)。
從機器學(xué)習(xí)的角度上,該方法主要從生成模型的角度出發(fā),因此模型的各個步驟解釋性很強,但是無法利用更多的特征,可以挖掘更多的特征并采用機器學(xué)習(xí)的方法來利用這些特征。
以上是潮人地東莞seo博客跟大家分享關(guān)于seo網(wǎng)站心得之搜索引擎同義詞反饋機制【百度搜索研發(fā)部】等問題,希望能對大家有所幫助,若有不足之處,請諒解,我們大家可以一起討論關(guān)于網(wǎng)站seo優(yōu)化排名的技巧,一起學(xué)習(xí),以上內(nèi)容僅供參考。






























