潮人地東莞seo博客小編下面跟大家分享關于seo網站心得之基于主特征空間相似度計算的切分算法等問題,希望seo專員在做seo優化的過程中有所幫助,內容僅供參考。

seo網站心得之基于主特征空間相似度計算的切分算法
我們為什么要切分?說到切分(segmentation),大多數人最容易想到的就是中文分詞。作為沒有天然空格區分的語言,切詞可以幫助計算機去索引文章,從而便于信息檢索等方面。該部分主要用到了分詞的一個方面:降低搜索引擎的性能消耗。我們常用的漢字有5000多個,常用詞組是幾十萬個。在倒排索引中,如果用每個字做索引的話,那么會造成每個字對應的拉鏈非常長。所以我們一般會用詞組來代替單個漢字建立索引。除此,切詞更重要的一個功能是幫助計算機理解文字,在這個層次上,切詞是不分語言的,任何一個語言,涉及到計算機去“理解”的時候,首先要做的,就是先去切分并在一定程度上消除歧義。這是因為,我們知道計算機本身擅長做的工作就是匹配計算。假設我們可以把每個字詞都指向一個語義,當輸入一個句子的時候,每個字對應語義的累加要弱于詞組語義的累加(因為單獨用字語義累加的瀘州網站seo優化怎么開戶時候,有個潛在的假設是字和字之間是獨立的),現在引入切分目的就是勾勒出字與字之間的關系,從而讓計算機更好的理解。
seo博客相關推薦閱讀:seo優化推廣:大連seo技術外包(大連seo全網營銷)
切分的難點在哪里?簡單的講,評價切分效果可以從三個層次來判定:切分邊界,切分片段,整個句子切分結果是否正確。切分邊界是指:相鄰的token(在中文切分中token可以認為是漢字,在英文中可以認為是單詞)之間是否應該被切開;句子級別是指,整個句子的切分結果是不是完全準確。切分片段是介于二者之間一種評估策略: 1. 切分結果片段中是否召回了需要切出的片段(recall); 2. 切分的結果中是否有錯誤的切分結果(precision)。下面我們從切分算法兩個重要的考量標準來闡述切分的難點,即新詞識別和歧義性的處理。
新詞:切分算法在召回方向上的難題主要為歧義現象和新詞的出現。如果一個切分算法無法識別新詞從而導致其未召回,最后會影響計算機對該切分句子的理解。前面我們有講,字到詞的過程可以讓計算機“假裝”理解這個詞的意思。比如最近的一個人名新詞“位菊月”,如果被切分算法切散后,計算機很難理解這個片段的含義,從而導致在諸如機器翻譯等應用中無法準確進行處理。
歧義性:切分算法要求解決切分片段歧義性,切分結果合理。漢字作為表示中文信息的載體,假設每個字/詞表示的信息有個上限,假設每種語言總體的信息量接近,由于常用字數有限,這些漢字之間就要有較多的組合形式來成詞并表達不同的語義。如果一個漢字可以同時作為2個詞的部分,當這2個詞按序出現時,就潛在包含了歧義。目前歧義主要分為2種:交叉型歧義,即相鄰歧義片段之間有若干token重復,比如“長春市長春藥店”,“長春市”與“市長”“長春”與“春藥”都是交叉型歧義片段。該歧義現象存在于任何語言的切分過程,比如針對英文,“new york times square”中的”new york times” 和”times square”;還有一種歧義為覆蓋型歧義,即token序列在不同語義下需要拆分開或合并在一起,比如“他馬上就來”和“他從馬上下來”,對后者來講,切分為“馬上”時則導致“從馬背上”的意思被“立刻的”意思所覆蓋。
除此,切分算法在應用中還要具備不錯的性能,在引入統計學習算法時,還要考慮人力在標注語料上面的成本。隨著時間的發展,語言也會進行相應的變化,只是在不同的領域會按照不同的速度演變著。因此,切分算法同樣需要與時俱進的優化。比如添加更多的詞進入詞典,更新重建語言模型(Language Model), 對于某些基于判別式(Discriminative model)切分的方法,比如CRFs,需要不定期更新人工標注語料來使得切分算法適應處理當前語料等等。
切分算法作為一個基礎的研究方向一直是很多科研人員努力奮斗方向,并產生出大量優秀的算法。在下面的章節中,我們簡單的介紹一些主流的、在工程中有著一定應用的切分方法。
切分的主流方法簡介在介紹我們的切分方法之前,我們先從2個方面來簡單介紹現有主流切分算法:即基于規則的切分方法和一些統計切分模型。
基于規則的切分方法基于規則的的切分方法主要表現為基于詞典匹配,如:正向最大匹配(Forward Maximum Matching, FMM),逆向最大匹配,最少切分(使每一句中切出的詞數最小)等等。
以正向最大匹配為例,其基本思想是:對于待處理文本,從左到右盡量匹配詞典中的最長詞,匹配到的詞即該處理文本的一個切分片段。假設詞典中有{百度,百度公司,中文,切分,算法}5個詞,則句子“百度公司的中文分詞算法”的正確切分結果為“百度公司|的|中文|分詞|算法”。
基于規則匹配的切分算法,缺點主要有2點:(1).無法很好的解決切分歧義問題。上述提到的三種方法都是從不同的角度嘗試去解決歧義問題,但是它們對于歧義消除的效果不顯著,特別當詞典詞增多的時候,詞與詞之間交叉現象加劇,該方法的歧義處理能力就會相應的減弱。(2).該方法無法識別新詞。在該方法下,線下挖掘大量的新詞加入詞典的收益和整體效果并非線性關系,詞典膨脹的同時,切分的歧義現象會更加嚴重。
由于該方法簡單快捷,因此針對上述缺點也有一些工作是將統計方法用在FMM上,該類方法主要運用貝葉斯模型(Na?ve Bayes)、互信息(Mutual Information)以及t-test chi-2等檢驗手段對有切分歧義的相鄰片段進行消岐。這方面可以參考“基于無指導學習策略的無詞表條件下的漢語自動分詞”等文獻。
統計切分模型統計切分算法主要利用語言模型、標注數據等資源,根據切分假設建立模型并利用其對應的資源進行模型參數優化,借助模型代替規則完成切分。
基于語言模型、Markov鏈的切分方法
對于一個待處理的句子
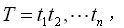
其每個處理的token(t_i,在中文分詞中可以認為是漢字,在英文中可以認為是單詞等)構成一個觀察序列,各種可能的切分片段即為隱含的狀態。該方法的目的即為觀察序列找一個最有可能發生的隱含狀態序列
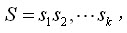
其中每個狀態status(s_i)即為詞典詞。整個切分過程即為了尋找一個可行的切分結果
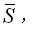
利用markov假設,使得達到maximum likelihood:
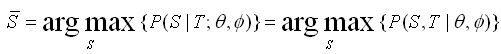
如果有了詞典詞的各種概率分布(可以通過利用語言模型進行極大似然估計,利用EM算法進行參數優化等得到),根據viterbi解碼算法,很容易就得到了切分結果。隨著語言模型的廣泛應用,以及各種learning算法的發展,該方法也具有廣泛的應用場景。深入閱讀的可以參考以下兩篇文章:《Self-supervised Chinese word segmentation》,《unsupervised query segmentation using generative language models and wikipedia》。
現在說說該方法的不足:
1. 在計算序列
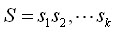
的概率時,我們依據markov假設,即:當前狀態僅僅和前面一個狀態相關。而在我們實際應用中,當前的狀態可以和前面狀態有關系,也可以和前面的前面狀態有關系,也可以不和前面的狀態有關系等等(這里面的是否有關系是在一定閥值條件下說的)。
2. 在估算詞典詞之間的概率分布時,EM作為一個常用的算法也有自身的不足。
條件隨機場模型(Conditional Random Fields )
CRFs是一個無向圖模型,它的目標是尋在在條件概率最大情況下的一種組合[Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data.]。在NLP技術領域中主要用于文本標注,應用場景主要為:分詞(標注字的詞位信息,由字構詞),詞性標注(Pos-Tagging,標注分詞的詞性,例如:名詞,動詞,助詞),命名實體識別(Named Entities Recognition,識別人名,地名,機構名,商品名等具有一定內在規律的實體名詞)。
它把切分的過程看作一個標注的過程,即對一個觀察序列中的token進行標注,比如標記為4中狀態:詞首(Begin), 詞中間部分(Middle),詞尾(End)和單獨存在(Single)。對于一個輸入序列
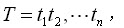
其標注序列為
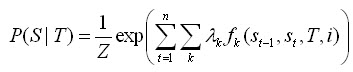
在輸入序列下的條件概率:
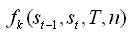
其中Z為歸一化函數,它等于所有可行標注序列條件概率的總和。
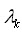
為特征函數(feature function),
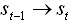
是其對應的權重。該特征函數用來在觀察序列T下,當前計算階段i下狀態序列
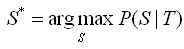
的情況。我們的目標是找到一個標注序列,使得上式達到最大值:
如果我們有了可以用于計算的各種概率分布,利用viterbi算法,不難獲得該序列的標注情況。再根據每個token的標注狀態(BMES)來進行切分。具體可以閱讀這篇文章《Chinese Segmentation and New Word Detection using Conditional Random Fields》。
CRFs模型中文分詞在一些封閉測試的語料中達到了非常可觀的準確率,在工業應用中,效果也是可圈可點。同時在中文分詞中,CRF分詞是基于漢字的構詞法進行,它可以有效地識別具有結構特征的新詞,而不在乎這個“新詞”是否在互聯網中出現過。CRF在分詞里面有2個明顯的不足:性能和代價。性能是在解碼階段需要耗費大量的計算量,代價是指,作為有監督學習,CRF模型的訓練需要大量的標注語料,同時,互聯網語料急劇增長和變化,CRF模型的更新也需要較多的人力。在后續我們會討論如何有效地將CRF模型融入工業化切分網站seo人工優化怎樣做應用中以及如何引入語言模型來更新統計切分模型。
除此,CRF模型在中文分詞上取得不錯的成績,能否直接移植到其它語言呢?語言特征和training語料間有怎樣的關系時整個切分算法才能出色的運行?有興趣的讀者可以思考這個問題。
在該節中,我們主要介紹了各種切分模型的原理,分析了他們的應用場景。在下面一節中,我們介紹一種新型的算法,它利用語言模型進行切分,它的假設是:如果兩個詞應該切分在一起,那么這兩個詞,在一定的條件下分布是接近的。
基于統計語言模型的無監督切分在本節中,我們會介紹一種新型的無監督切分算法(Query Segmentation Based on Eigenspace Similarity),相對于基于HMM(隱馬爾可夫模型,Hidden Markov Model,方法備注)的方法來講,他充分考慮了切分片段整體信息,并且在后面的章節中,我們會介紹該方法有很好的拓展性,從各個角度來講都符合我們在最初提出的切分難點的解決。
在介紹具體算法之前,我們說說該算法的假設。對于A B兩個token,他們可以切分在一起就說明他倆在一定條件下緊挨著出現,換句話說,在一定條件下(即整個待切分句子的上下文環境),他倆的數據分布是比較相似的,如果我們可以獲得其數據分布(vector),再計算這兩個vector之間的相似度,就可以決定這兩個token是否應該合并在一起。這個方法聽起來似乎和互信息(Mutual Information)有點像,但是互信息并沒有考慮我們前面說的一定條件下,不過也有一些工作針對MI這點引入了cosine of point-wise mutual information。即便考慮了上下文信息,還有個問題比較棘手:判斷兩個token是否應該合并在一起的閥值應該是多少?在有些工作中[Generating query substituti懷化seo網站排名優化ons],這個閥值被經驗地設置為一個定值,事實上,這樣做可能是不大合理的。在各種各種下,我們構建了這樣一個切分的上下文環境,并且巧妙地把統計特征投影到其主特征空間(principal eigenspace,在線性代數中,特征空間是由一個矩陣的所有特征向量張成的空間,主特征空間是有該矩陣的主要特征向量張成的空間。相比較特征空間,主特征空間可以覆蓋特征空間大部分信息,并且可以輔助相關應用進行有效的降維、除噪和數據變換等),計算相似度,配合主特征空間的維度進行切分。
算法流程我們以一個例子來講述該算法是如何工作的,有興趣的讀者可以閱讀該文[Query Segmentation Based on Eigenspace Similarity]。(點擊查看大圖)
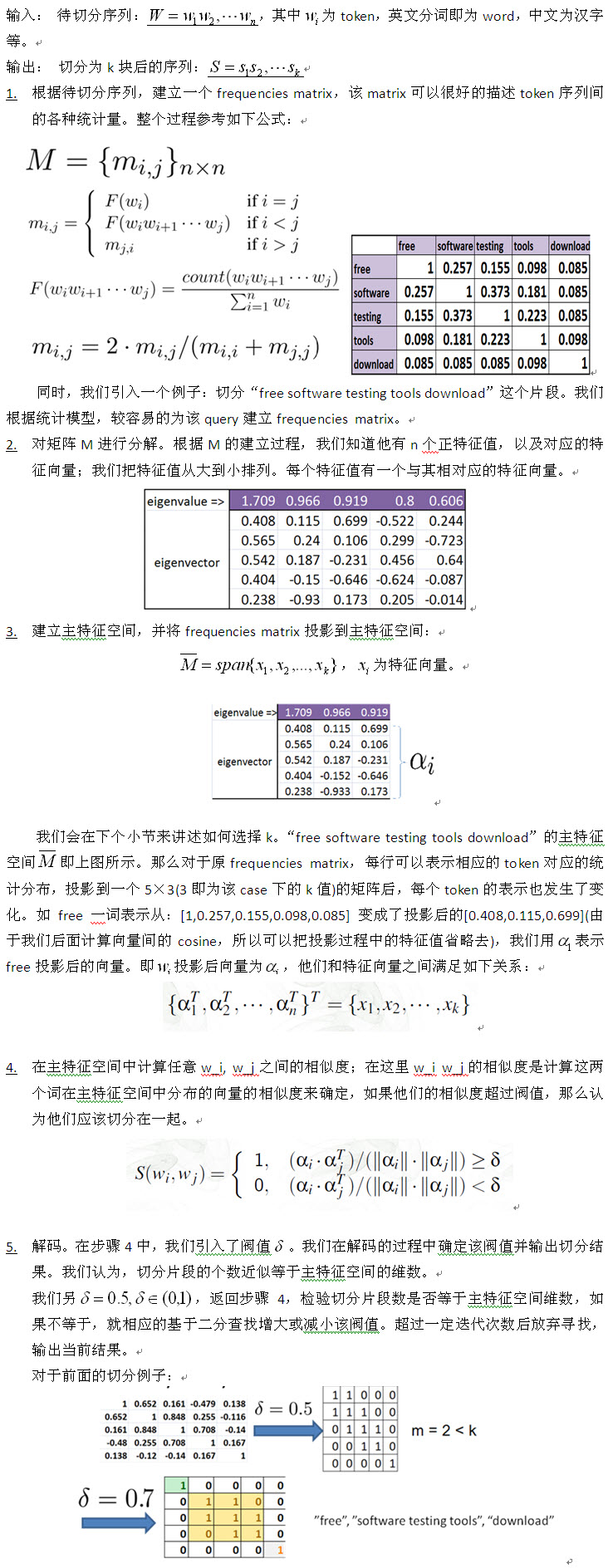
算法分析該算法一個核心的要點為主特征空間維度k的確定。換個角度講,對于給定一個待處理串,如果事先知道切分的片段數,利用一些簡單的統計策略如MI已經可以較好的做切分。
關于參數k的確定,論文中給出一種簡單的判斷方法。這方面也有相關的一些研究方法,有興趣可以深入閱讀譜聚類(spectral clustering)以及Principal Component Analysis, Springer (2002)一書中的第六章” Choosing a Subset of Principal Components or Variables”。
該切分算法根據數據分布入手,由切分片段特征展開假設,通過基本token在一定相關語義下統計分布而進行切分。相對基于EM/HMM等模型的無監督切分算法,該方法一個明顯的優點是充分考慮了整個切分片段的信息,而不是相鄰token之間的統計量;同時,該方法通過空間變換等手段,有效的進行數據除燥等策略,從而是數據分布更趨于真實情況。
同CRF等有監督學習相比,該方法的輸入為ngram語言模型,不需人工標注數據 ,同時本方法可以識別新詞,這在互聯網應用中極具優勢。同時針對不同語言不通領域,我們只要提供足夠可靠的語言模型就可以在很大程度上解決他們的切分需求。
當然本方法(or無監督切分方法)在切分的準確率上和基于有監督的模型相比仍有差距,我們在下節會闡述這個問題,并給出一個我們勾畫的切分體系。
如何打造一個好的切分框架簡單的說:
詞典是需要的,并且有有效的手段源源不斷的更新詞典詞,在不同的應用需求下,這些詞典詞在切分體系中的位置和作用可能不一樣。強大的語言模型是需要的。原因是:如果A B兩個token應該切分在一起,那么“AB”這個組合就應該在互聯網中大量出現。人工標注的數據也是必要的,這是因為,切分作為人們對句子一個主觀的認識,這個和數據在語料中的分布不是完全一致的。
先說說有監督和無監督兩種方法的差異。如果無監督的效果可以趕得上有監督的方法,那么有監督方法就可以徹底和分詞說拜拜了。那么無監督方法切分效果瓶頸來源于哪里呢?這里用一個例子來解釋。很多用戶在在遇到不認識的字時候,會通過如下手段去搜索學習,query“**頭上加一??”,如“旦頭上加一橫是什么字”等等,由于無監督學習是根據數據的分布出發,在這樣的case中“頭上加一”或者“加一”就會被切分出來。事實上,這種切分方式和人們的認識是不一樣的。這是一個極端的例子,數據分布和人們主觀認識不一致有很多因素。
我們在使用有監督的方法解決問題是,主要著眼點在考慮local consistency,也就是說,所有的工作是基于已經標注的數據進行開展,標注語料決定了最后的算法效果;而無監督方法更多的是從全局的數據分布(global consistency)來看,如果某個需求下數據具備全局的結構特征,則無監督模型也可以很好的對其進行解決。
那么在這里我們就有個設想,引入部分的標注數據來改變數據的原始分布,最后優化切分效果。半監督學習(semi-supervised learning)的引入即可以在很大程度上提升無監督切分的效果。我們之所以引入介紹無監督切分算法,是因為該方法可以和現有的半監督學習算法相結合。
結合上面所說的,描述一下我認為一個好的切分體系應該是什么樣子。
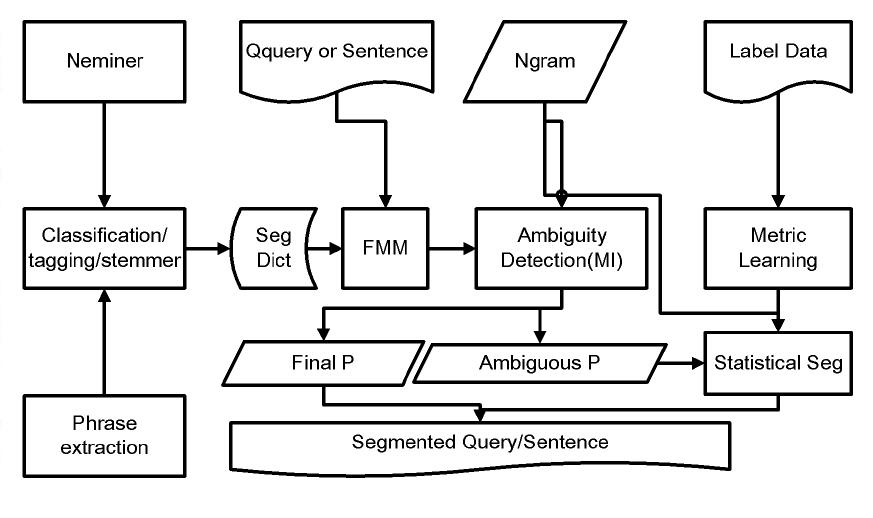
我們需要詞典。詞典的來源有很多,比如專名挖掘(NE mining), 詞組挖掘(Phrase Extraction)。同時我們還要有個模塊對這些資源進行不同程度的加工,最后提供一個詞典給正向最大匹配(FMM)切分使用。我們會在后續的章節中,介紹新詞挖掘,資源抽取等技術。我們之所以使用FMM是因為本算法可以完美地處理很多待處理語句。只有在FMM無法解決的時候,我們才會引入統計切分算法。這個時候,我們需要一個trigger來負責這件事,就如上圖中的Ambiguity Detection模塊。這個模塊可以把一個句子分成2種形式,可以通過FMM處理的簡單句,需要統計模型處理的復雜句。對于復雜句采用統計切分,最后把二者結果merge起來。統計模型的方法有很多,在這里自然要推薦文中所述的模型。該模塊輸入為ngram語言模型。統計切分算法的優化過程是引入標注數據來改變ngram中token之間的分布。在這里,我們推薦使用metric learning的方法,直接對frequencies matrix進行改動。切分的bad case也可以通過標注數據來修復。
在這種體系下,我們很好地解決了切分過程中存在的一致性、歧義處理、新詞、可持續提升、可擴展性、性能等因素。
切分作為自然語言處理中一個最底層的工作,有大量的學者在這方面進行不斷的研究。在中文分詞方面,清華大學的自然語言處理同學收集了這方面的論文,有興趣的讀者可以根據需要進行相應的擴展閱讀。
百度自然語言處理在中文分詞上做了相當多的工作,在后續,我們會從切詞中遇到的技術和資源進行展開討論。
以上是潮人地東莞seo博客跟大家分享關于seo網站心得之基于主特征空間相似度計算的切分算法等問題,希望能對大家有所幫助,若有不足之處,請諒解,我們大家可以一起討論關于網站seo優化排名的技巧,一起學習,以上內容僅供參考。






























